
A particular set of probabilistic inference algorithms common in robotics involve Sequential Monte Carlo methods, also known as “particle filtering,” which approximates using repeated random sampling. (“Particle,” in this context, refers to individual samples.) Traditional particle filtering struggles with providing accurate results on complex distributions, giving rise to advanced algorithms such as hybrid particle filtering.
Hybrid particle filtering algorithms use heuristics during their computation, which can often lead to inefficient computation and less accurate results. But a team from MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) recently published a paper presenting programming interfaces they call “inference plans” that enable developers to carefully augment these algorithms’s heuristics to control their speed and accuracy.
A key consideration is that not all choices the developer can make to control the algorithm are viable. The CSAIL project therefore also introduces SIREN, a new prototype probabilistic programming language (PPL) that allows program developers to use annotations to specify which plans they want to implement, and then the programming language automatically determines if their plans are actually viable.
“Lots of people write custom code to perform inference with hybrid particle filtering in a specialized way to improve performance,” says CSAIL PhD student Ellie Cheng, lead author on the new paper with colleagues from the group of MIT professor Michael Carbin. “Our work is focused on improving domain-specific languages designed for people using hybrid particle filtering so they can avoid the extra work.”
SIREN provides a flexible syntax for defining probabilistic models, including features like random variable declarations, statements for conditioning, and the ability to specify inference strategies (symbolic or sample).
The team showed in experimental tests that the control provided by inference plans enabled speed-ups of roughly 1.8x compared to the inference plans implemented by default heuristics; the results also show that inference plans improve accuracy by 1.83x on average and up to 595x with less or equal runtime, compared to the default inference plans.
“It was interesting to uncover that inference plans do, in fact, make a difference, and I was surprised to see that it’s something that can be applied to not just one algorithm, but different hybrid particle filtering algorithms,” Cheng says.
As an example of how developers can use inference plans to improve inference performance, the researchers used the example of a radar tracker that tracks a plane’s movement by estimating its position x and altitude alt over time. In representing the radar tracker as a probabilistic model, you can capture both the plane’s movement noise q and also the radar’s measurement noise.![]() In the future, the team wants their system to be able to tell the user a ranking of viable inference plans, versus being able to glean the simple binary of whether something is viable or not.
In the future, the team wants their system to be able to tell the user a ranking of viable inference plans, versus being able to glean the simple binary of whether something is viable or not.
“This is a promising approach for improving inference efficiency in probabilistic models, with the potential to broaden the applicability of probabilistic programming to complex real-world modeling tasks,” Cheng says.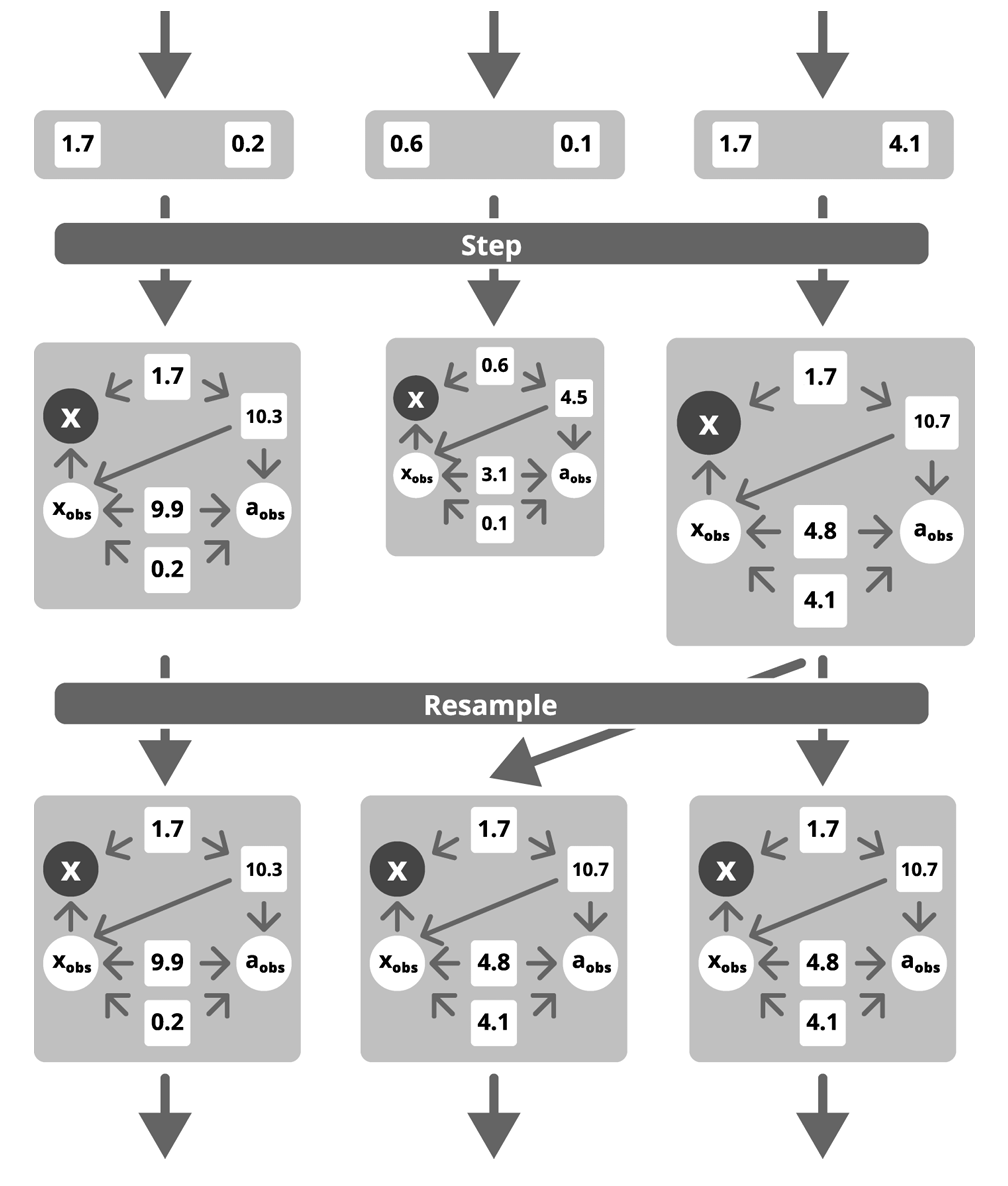 The figure above depicts hybrid inference using particle filtering as the approximate inference method. The algorithm maintains a collection of parallel instances of executions, represented by the big boxes. Each instance contains a symbolic structure that encodes certain random variables symbolically, as shown by the circles in the diagram; other random variables are encoded as constant samples drawn from probability distributions, depicted as squares. The sizes of the boxes correspond to the associated weight, which indicates how likely these instances are based on observed data (the white circles). The instances execute in parallel until they hit a checkpoint at which they are resampled, meaning the distribution of instances is adjusted based on the weights. The arrows between each box indicate the transition or transformation of a particle from one stage to the next, including when a particle is duplicated during the resampling step.
The figure above depicts hybrid inference using particle filtering as the approximate inference method. The algorithm maintains a collection of parallel instances of executions, represented by the big boxes. Each instance contains a symbolic structure that encodes certain random variables symbolically, as shown by the circles in the diagram; other random variables are encoded as constant samples drawn from probability distributions, depicted as squares. The sizes of the boxes correspond to the associated weight, which indicates how likely these instances are based on observed data (the white circles). The instances execute in parallel until they hit a checkpoint at which they are resampled, meaning the distribution of instances is adjusted based on the weights. The arrows between each box indicate the transition or transformation of a particle from one stage to the next, including when a particle is duplicated during the resampling step.



